What I Learned This Week #6
What I Learned This Week #6
Data Partitioning, ACID Transactions, AWS Lambda Internals, Rust Atomics, and Logging.

👋 Hi, this is Gabriel with this week’s learnings. I write about software, startups and things that interest me enough to learn about. Thank you for your readership.
This week I’m sharing my top learnings about data partitioning, ACID transactions, AWS Lambda internals, Rust atomics, logging, and more. Hope it is helpful!
Learned while reading
Read Designing Data Intensive Applications Chapter 6 & 7, Understanding Software Dynamics Chapter 8, ByteByteGo’s AWS Lambda Under the Hood, and Rust Atomics and Locks Chapter 1 & 2.
Data partitioning primarily aims to enhance scalability by distributing large datasets across multiple disks and processors to manage query loads and is often combined with replication to enhance data record fault tolerance. While there's an overhead due to network latency and coordination, partitioning is the only option when the dataset is larger than a single machine can hold. Partitioning involves various considerations such as rebalancing (copying data to maintain even distribution when adding or removing nodes), distributed query execution when data is spread across multiple partitions, and handling hot spots and skew (where a specific partition receives the majority of requests, defeating the purpose of partitioning). Effective partitioning algorithms should be deterministic, avoid skews, and ensure uniform distribution, with the choice between range-based and hash-based partitioning depending on the workload; range partitioning is particularly favorable for analytical queries due to data adjacency.
Secondary indexes also need to be partitioned, and there are two main methods for doing so. Local indexes place the secondary index on the same partition as the primary key and its corresponding value. This approach keeps related data together but a read of the secondary index requires querying multiple partitions. Global indexes, on the other hand, are partitioned separately, using the index values themselves as the partitioning key. This can provide faster lookups for certain queries but may introduce additional complexity in maintaining consistency across partitions since several partitions of the secondary index need to be updated on write. It’s always a tradeoff between read and write performance.
When data is partitioned across machines, routing queries becomes an issue since rebalancing will cause the location of data to change. Because of this, many distributed systems use separate coordination services like ZooKeeper as the source of truth for mapping partitions to nodes. Other distributed systems take a different approach and use a gossip protocol among the nodes to disseminate any changes in cluster state. In these systems, requests can be sent to any node, and that node forwards them to the appropriate node for processing.
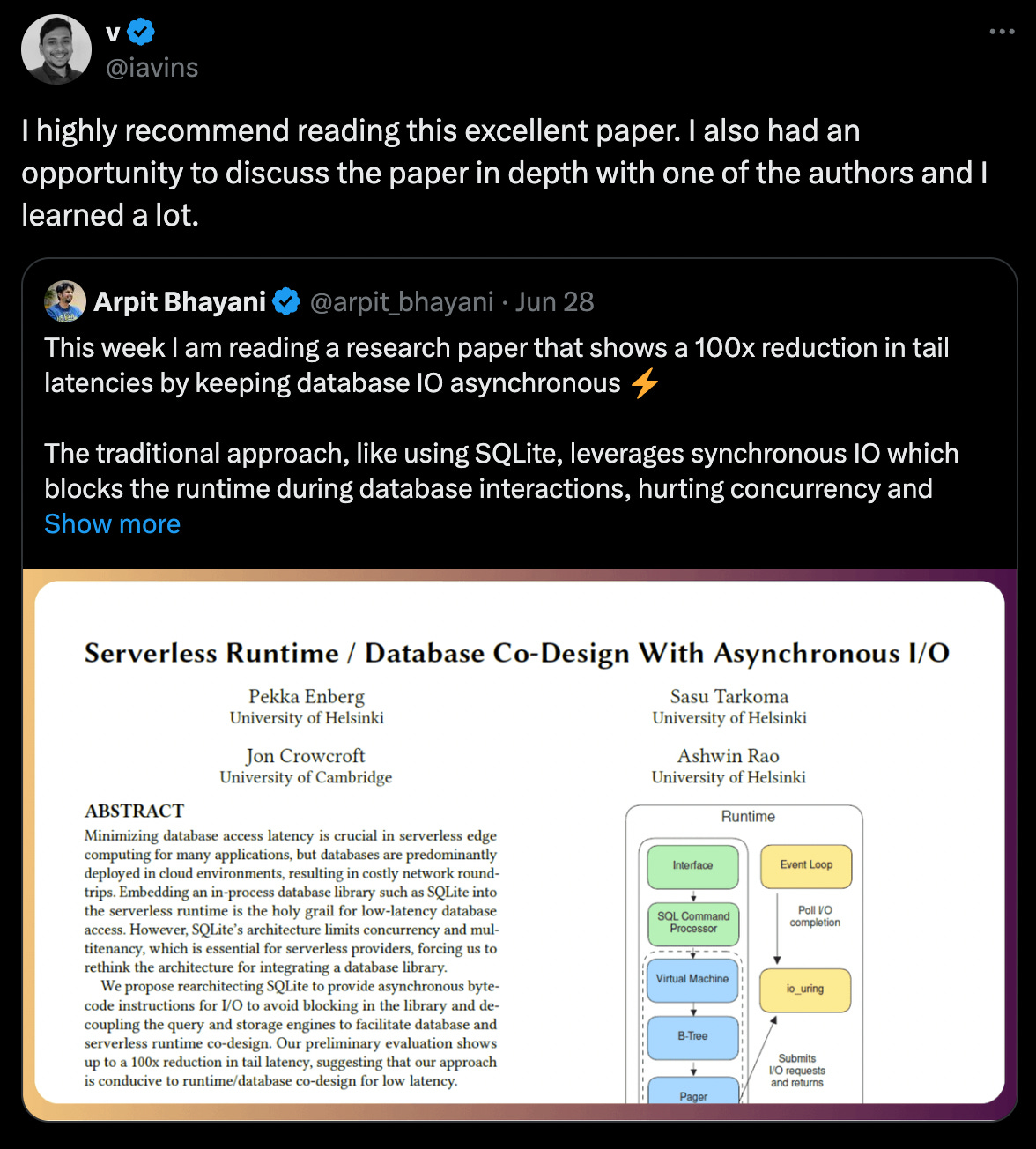
Transactions are an abstraction layer that allow an application to pretend that certain concurrency issues (e.g., race conditions) and certain software failures (e.g., partial failures) don’t exist. Regarding software failures, transactions simplify error handling by preventing partial failures. This approach makes it safe to retry operations, as a failed transaction triggers a rollback, undoing any incomplete tasks. Consequently, the system returns to a known state, eliminating the uncertainty that would otherwise make retries unsafe. With regards to concurrency, transactions provide varying levels of isolation between concurrent operations, depending on the isolation level chosen. The degree of isolation ranges from Read Uncommitted to Serializable, with Serializable being the strongest level that ensures transactions behave as if they were executed serially. While serializability offers the strongest guarantees, it's often avoided due to performance costs. In practice, weaker isolation levels like read committed or snapshot isolation are common, balancing consistency and performance. Regardless of the chosen level, transactions still provide a framework for handling concurrency issues (a.k.a race conditions) through mechanisms such as row-level locking, optimistic concurrency control (compare-and-set operations), and multi-version concurrency control (MVCC), helping developers reason about and control the interactions between concurrent transactions. Transactions can be implicit (automatically applied to single statements) or explicit (manually defined blocks of operations with BEGIN and COMMIT).
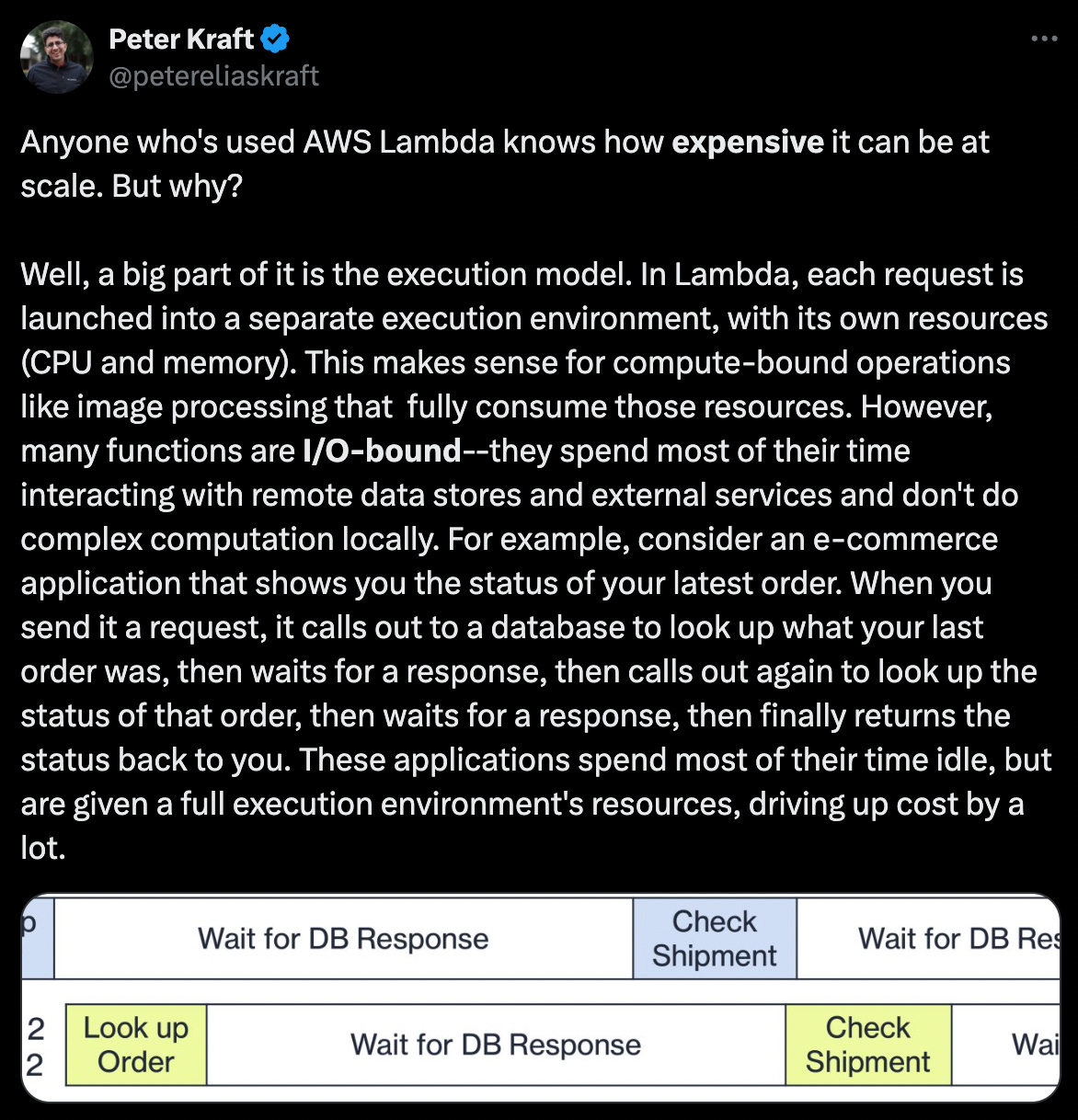
Internally, AWS Lambda employs a worker model for task execution. Its assignment service, responsible for distributing tasks, is partitioned and replicated using a single-leader approach for consistency and fault tolerance. The architecture utilizes Firecracker VMs, which are lightweight virtualization technology for improved isolation and resource efficiency. For storage optimization, the system implements several techniques: chunking to load only required parts of your container image, convergent encryption for secure sharing of common data, and VM snapshots (introduced in 2022 for Java only) to improve cold start performance.
Memory reordering—an optimization technique in CPUs and compilers used to improve performance by allowing memory operations to be executed out of order—poses challenges for concurrent programming. For example, memory reordering can cause changes made by one thread to become visible to other threads in an order different from what the programmer intended. Atomics provide a solution by offering a programming abstraction that maps to indivisible hardware-level operations. These atomic operations are not only used for thread synchronization but, unlike in higher-level languages, in Rust they also allow developers to control memory reordering requirements across different threads for both the compiler and the CPU. Rust allows various levels of memory ordering guarantees, from relaxed (offering minimal guarantees but maximum performance) to sequentially consistent (ensures a total order of operations across all threads at the cost of performance). This low-level control allows for the implementation of efficient, lock-free data structures without the overhead of full mutex locks.
A log is a timestamped sequence of events stored in files. These files may be in binary format for compactness, text format for direct reading by people, or Protocol Buffers format for a balance of readability and performance. Log files are typically stored locally and then migrated to a log repository for longer-term storage. In Rust, the programming language provides a logging API abstraction, with various implementations available from the community to choose from.
Learned while listening
Wes McKinney discusses how the performance one can get out of a CPU is hitting a wall. Therefore, GPU-accelerated data processing presents a very promising future. His advice: Go learn CUDA!
Aravind Srinivas prefers using AWS not only for its great quality but also because it's a popular skillset among developers. This popularity makes it easier to recruit developers with AWS experience, resulting in more efficient onboarding and shorter time to productivity. I personally attribute this to AWS's strong focus on certification programs and the availability of online training for developers, which is often free or very affordable.
The operating system's thread scheduler typically lacks fine-grained control over thread scheduling policies. This limitation results in a single thread being able to service only one socket at a time, as it must block the entire thread when performing I/O operations which significantly increases tail latency for network requests in web servers. To overcome this, many systems avoid relying on the OS scheduler and instead implement a user-space scheduler. This approach can schedule multiple socket operations on a single thread, optimizing latency and not relying on the OS thread scheduler for concurrency. This strategy employs I/O multiplexing, which comes in two main variants:
The reactive approach (e.g., Linux epoll and BSD kqueue)
The proactive approach (e.g., Windows IOCP, Linux IO_URING)
For systems without kernel-level non-blocking I/O, user-space implementations are necessary. These typically involve two types of thread pools: one for blocking operations and another for non-blocking operations (e.g., Rust's Tokio). Cross-platform alternatives to IO_URING exist, such as the approach used in TigerBeetle.
Samir Vasavada discusses his regrets about initially hiring mostly senior executives. He explains that many senior executives typically have their own playbook that worked at big companies. However, instead of thinking from first principles, they attempt to apply this playbook to a startup, which is a very different environment.
Learned while scrolling