What I Learned This Week #5
What I Learned This Week #5
Data Replication, Measuring Networks, Database-as-a-queue, and Serverless.

👋 Hi, this is Gabriel with this week’s learnings. I write about software, startups and things that interest me enough to learn about. Thank you for your readership.
This week I’m sharing my top learnings about data replication, measuring networks, database-as-a-queue, serverless, and more. Hope it is helpful!
Learned while reading
Read Designing Data Intensive Applications Chapter 5, Understanding Software Dynamics Chapter 6 (again), Database-as-a-queue blog’s including EnterpriseDB’s Listening to Postgres and Twilio’s Centrifuge, Serverless blog’s including DBOS’ How DBOS Makes Stateful Serverless 15x Cheaper and The Architect’s Elevator’s The Serverless Illusion, and the Learning Rust With Entirely Too Many Linked Lists Chapter 4.
Involving multiple machines in the storage (write) and retrieval (read) of the same data set typically requires two methods: replication and partitioning. Replication copies data to multiple machines, which improves availability by maintaining data access even if some machines fail. It also reduces latency by distributing replicas geographically, bringing them closer to customers in different regions.
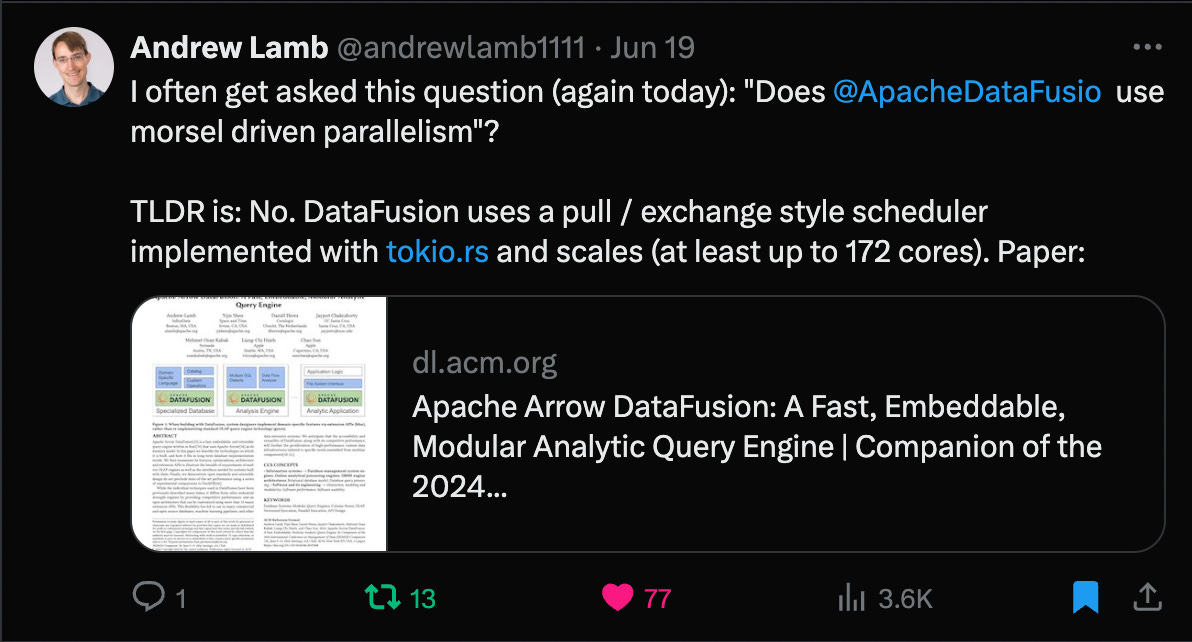
Single-leader replication is a common strategy where one machine called the “leader” accepts writes and forwards a log of data changes (write operations) to its “followers”. Followers apply these changes in the same order, maintaining consistency with the leader's data. This approach increases read throughput by allowing reads from any machine, while write throughput is limited to that of a single machine. A key advantage of having a single writer is the clear global event history, which prevents write conflicts and dramatically simplifies implementation. Several data management systems offer single-leader replication features: MySQL, PostgreSQL, & Kafka.
Leaderless replication is a common strategy for applications that prioritize availability and scalability over consistency. By allowing any node to handle both read and write operations, this approach improves performance and fault tolerance compared to single-leader systems. However, it introduces challenges such as the need for write conflict resolution. To maintain a balance between consistency and performance, leaderless systems often employ quorum-based operations (a quorum is the minimum number of “votes” needed to obtain in order to be allowed to perform an operation) where clients send each write to several nodes, and read from several nodes in parallel in order to detect and correct nodes with stale data.
Regardless of the strategy, replication can be either synchronous or asynchronous. In synchronous replication, the replica that receives a write request must confirm that all or a subset of the other nodes in the cluster have applied the data changes before the node can acknowledge the write to the client, ensuring strong consistency but increasing latency. In asynchronous replication, the replica that receives a write request acknowledges the write to the client immediately after committing it locally, and the other nodes update at their own pace, which can lead to temporary stale reads and, more importantly, data loss if the node that received the write request commits local changes, acknowledges the write to the client, and crashes before replicating the changes to the other nodes. In reality, it is not practical for all followers to by synchronous, since a single crashed follower would block all writes.
Sending data over the network is delivered with a high probability, but it is not 100% guaranteed to arrive. One of the primary reasons for this is that many physical network components, such as switches and routers, drop packets as a necessary mechanism to manage network congestion during periods of heavy traffic.
Postgres'
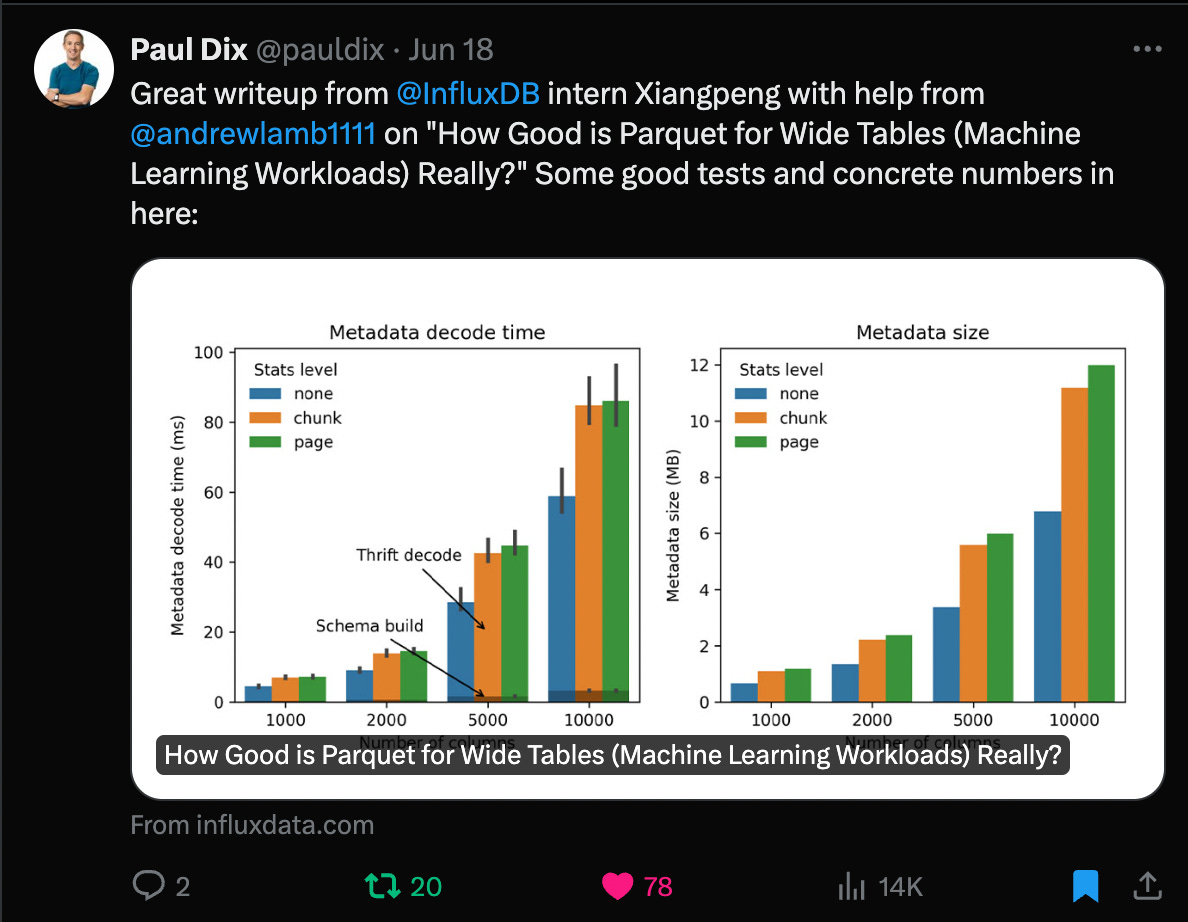
FOR UPDATE SKIP LOCKEDandLISTEN/NOTIFYfeatures enable two different approaches to the database-as-queue architecture, offering an alternative to traditional task queues for many workloads.FOR UPDATE SKIP LOCKEDallows for a queue-like behavior in Postgres that allows multiple workers to dequeue tasks without conflicts, as locked rows are skipped, preventing race conditions.LISTEN/NOTIFYprovides a publish-subscribe behavior that allows real-time notifications when new tasks are available, reducing the need for constant polling, but offer weak message guarantees in the presence of network issue or client failures, so it should be used in conjunction with polling. Key advantages of database-as-queue include easy task reordering. While traditional queues often struggle with changing execution order without copying large amounts of data, databases can simply modify the query used to select tasks, efficiently altering priorities without data duplication. Additionally, supporting tens of thousands of virtual queues is not feasible with most traditional queues; those that do support this are prohibitively expensive. In contrast a database can simply filter on a queue identifier column. These features make databases viable for many workloads where traditional queues struggle or become cost-prohibitive.The serverless programming model presents two main challenges: complexity and cost. While serverless architectures reduce operational complexity, they shift the burden of managing the complexities of distributed systems to developers. This is because what looks like a simple function is really a distributed service invoked by a queue that brings along issues like cold starts, execution time limits, concurrency management, and more. In particular, serverless platforms like AWS Lambda launch each concurrent request in a separate environment, charging for total execution time including idle periods. This approach is particularly inefficient for IO-bound functions, which spend significant time waiting for operations to complete. As a result, cost optimization becomes a major concern for developers. Durable executions in a serverless environment offer a promising solution to provide developers with the functionality while eliminating, or at least reducing, the concerns of distributedness.
In Rust, smart pointers can be used to get shared access through reference counting to track how many parts of the program are using a particular piece of data. This allows the language to automatically manage memory by freeing the data when it's no longer needed (i.e., when the reference count drops to zero). For single-threaded scenarios,
std::rc::Rcis used. However, to ensure thread safety, the reference counting must be an atomic operation, which is provided bystd::sync::Arc. Since atomic operations are more expensive, Rust offers both options, allowing programs that don't require thread safety to avoid the overhead of atomicity.
Learned while listening
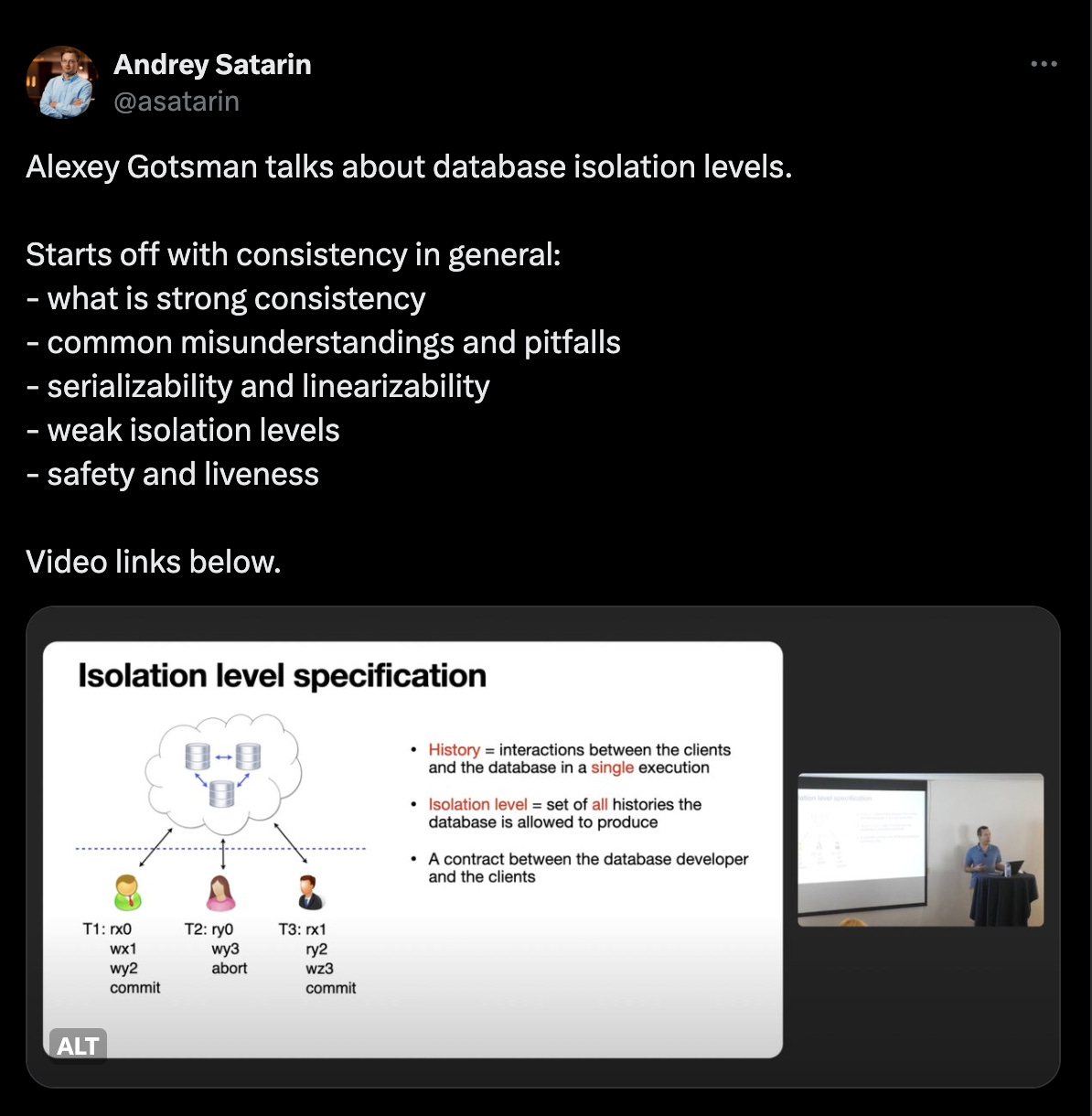
This Apache Parquet talk offers valuable insights beyond its primary topic. It explores the separation of physical and logical storage layout models and various data sources and formats.
Danny Rimer of Index Ventures notes that in tech, marketing is passive activity that results from great products. However, some companies like Apple and Airbnb focus deliberately on branding. Rimer encourages entrepreneurs to think proactively about branding, emphasizing it as a real competitive advantage.
Deliberately focusing on building a brand is much more common in industries outside of tech. Ben Gilbert examines gross margin to gauge brand strength of automobile manufacturers, as it reveals how much these companies can mark up prices over cost of goods sold (COGS) to their customers. Examples include BMW (17%), Mercedes (23%), Porsche (29%), Ferrari (48%). Ferrari buyers, in particular, prioritize the brand over cost cause…it’s a Ferrari.
Bill Gurley and Brad Gerstner discuss challenges companies face when going public in today's environment. They argue that many companies are too hesitant to go public and confront their current, likely lower valuations compared to previous funding rounds. They suggest that delaying this process hurts companies by preventing them from facing reality and taking appropriate action.
Learned while scrolling